




At Peakflo, we send thousands of PDFs per day to our customers. These include invoices, statements of accounts, or on-demand reports attached to emails or directly downloaded on-demand through the UI.
To achieve this, we had to build a fast, reliable, and scalable system that could handle multiple tasks at once.
Tech Stack and Libraries
Since our primary tech stack is based on Javascript and NodeJs (MERN) on the Google Cloud Platform (GCP), we had to stay within the boundaries of our existing infrastructure to build the system.
When it comes to generating PDFs using NodeJS, there are numerous libraries available, but the most flexible and recognized method is the “Puppeteer” package.
It provides APIs to control headless chromium and HTML/CSS to craft PDF templates. We also use “handlebars” to create templates for easier writing and compiling.
Additionally, we resorted to cloud functions hosted on GCP since they respond to on-demand requests and can scale up or down as required. GCP will also take care of the provisioning, maintaining, and scaling of the infrastructure.
Ever since Google announced the support of headless Chrome in “App Engines” and “Cloud Functions”, all the required dependencies will be available in the environment to run Puppeteer.
Implementation Details
Design And Architecture
Here’s what a simplified PDF generation flow looks like. Every stage/function is triggered based on an event to make a completely asynchronous system.
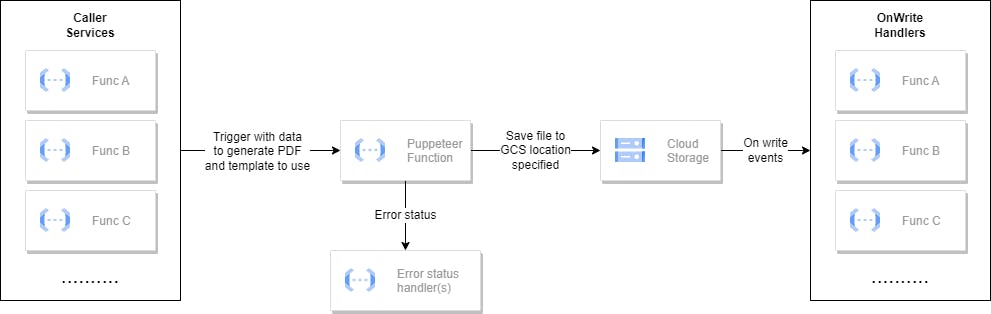
The caller services will trigger an event for the Puppeteer service to generate a PDF with the necessary data and the location it should write to in the Google Cloud Storage (GCS).
Template generation using “handlebars” and PDF generation are coupled in a single service for simplicity. Here’s what an event to Puppeteer service looks like:
{
"eventId": "<event UUID>",
"timestamp": "<timestamp>",
"templateName": "<template name>",
"writeLocation": "<write location/storage location in GCP>",
"data": {...data for interpolation}
}
Once the Puppeteer service completes the PDF generation, it will write the resulting file in the GCS in the location specified in the event payload.
Since GCS supports write events, every successful write contains information about the location where it is written, so the handlers know where they should resume the flow.
Generating PDF
As the function is invoked, the first thing to do is to start the browser:
const browser = await puppeteer.launch();
Then, use templateName to find the handlebars template to use and compile the template with the inputted data.
const compiledTemplate = Handlebars.compile(templateString)(data);
Now, using the browser, load a new page with the compiled HTML template. Notice how we convert the HTML template to base64 and load the content on the page.
const page = await browser.newPage();
const content = Buffer.from(compiledTemplate).toString('base64')
await page.goto(`data:text/html;base64,${content}`, { waitUntil: 'networkidle0' });
Now, print the PDF then close the page and browser to avoid leakage or long-running functions which can potentially result in a timeout.
const pdf = await page.pdf({ format: 'a4' });
await page.close();
await browser.close();
Handling Errors
In case of errors, there's an error status handler in place that updates the result of the generation.
To simplify it, the same GCS write flow could be used and the Puppeteer service could write an error file on location. On-write events should be written to support the error file writes.
Implementation Challenges
One could face problems if using URLs in templates to display images while generating PDFs using Puppeteer. Your PDFs might end up not showing pictures completely or not all of them.
To fix this, you'll need to give the Puppeteer enough time to load images, which can result in a process slowdown. Instead of passing URLs to be interpolated, every caller service should ideally pass the image data as base64. This way, the Puppeteer doesn’t have to wait for images to load.
Using base64 for an image doesn't require any template change. You'll only need to prefix the base64 with image mime so it is correctly parsed. Here's how the base64 for the image should look like:
"data:image/png;base64, iVBOR...."
It's important to note that doing base64 conversions for images can increase the payload size of the Puppeteer functions.
It is also possible to hit the payload size limitation of your event queue, which in our case is 10MB for pub/sub.
Since our use case only needs the use of logo images in PDF, we also compress this file and resize it when it's uploaded into our system.
This solution worked quite well for us. If you need more complex image usage, consider adding waitUntil options to Puppeteer and stick to the use of image URLs
Results
Performance
Our performance test of Puppeteer on the cloud function shows that although 512MB of memory is supposed to be sufficient to run Puppeteer alone, it performs best on memory with 1 GB allocation.
This is because the function can crash – especially if there are other operations being performed, such as writing to the GCP and updating the database.
In terms of the execution time, we've observed the following:
Starting the browser (Puppeteer) takes around 3.2 seconds.
Generating the PDF takes approximately 1.5 seconds.
Uploading it to the GCS takes around 0.5 seconds.
Additional 0.5 seconds for the audit as well as generating the final template with data.
That results in a total function execution time of ~5.7 seconds. The fact that starting a browser takes 3.2 seconds means it's a resource-intensive task and has a cost.
To solve this, we resorted to generating multiple PDFs per invocation where possible to not only reduce the PDF generation time but also the number of function invocations to reduce the cost.
Multiple Generations Per Invocation
Most of the resources are consumed to start the Puppeteer per invocation.
To reduce resource utilization in cases where mass generation is required, we built the Puppeteer service to generate multiple PDF files in a single run.
This needs a change in the event we specified earlier to support compound generation information.
{
"eventId": "<event UUID>",
"timestamp": "<timestamp>",
"files": [
{
"templateName": "<template name>",
"writeLocation": "<write location>",
"data": {...data for interpolation}
}
]
}
Once the browser is initiated, we use the same browser instance to load multiple pages in parallel and print their PDFs. Here's what it looks like:
const browser = await puppeteer.launch(); // start browser
// for each file generate PDF (make sure to handle errors here)
await Promise.all(generatedTemplates.map(async (template) => {
const page = await browser.newPage();
const content = Buffer.from(template).toString('base64')
await page.goto(`data:text/html;base64,${content}`, { waitUntil: 'networkidle0' });
const pdf = await page.pdf({ format: 'a4' });
await page.close();
return pdf;
}))
It's also important to take into consideration that loading multiple pages in parallel can increase the memory utilization of a function. Thus, it is important to limit the number of files the function can process at the same time. For us, that number was 10.