




Introduction
Internal teams of an organization need a mechanism to quickly and accurately obtain the information they need from the vast amount of internal documentation. Large Language Models like GPT and PALM are good at answering generic questions, but they are not trained on a company's internal data. Retraining these models for company-specific data is a time-consuming and costly procedure. This is where Retrieval Augmentation Generation (RAG) comes to the rescue.
Retrieval Augmentation Generation (RAG) is a state-of-the-art natural language processing model that has gained popularity in recent years. RAG combines an information retrieval component with an LLM. This allows RAG's internal knowledge to be modified efficiently and without requiring retraining of the entire model.
RAG takes the input and retrieves a set of relevant/supporting documents from a source (e.g., Notion, Help portal). The retrieved documents are concatenated as context with the original input prompt and fed to the LLM, which produces the final output. This makes RAG adaptive for situations where facts could evolve over time, which is useful as LLMs' parametric knowledge is static.
RAG enables access to the latest information for generating reliable outputs via retrieval-based generation without requiring retraining of the language models. By using this approach, teams can avoid the time-consuming process of manually searching through documents and instead rely on the model's ability to recognize patterns and extract relevant information. This can ultimately lead to improved productivity and more efficient decision-making.
Key highlights of the RAG-based setup
A clear indication of the source upon which the answer was based, allowing for validation of the answer returned by the generator/model.
Very unlikely to hallucinate. By restricting our generator component to the corpus of our knowledge base, it will admit it can’t formulate a response when no relevant sources were found by the retriever/matching engine.
Maintainable Search Index. A knowledge base is a living thing, and when it changes, we can adapt our Search Index to reflect those changes.
Refer to this article for more info on RAG.
Architecture
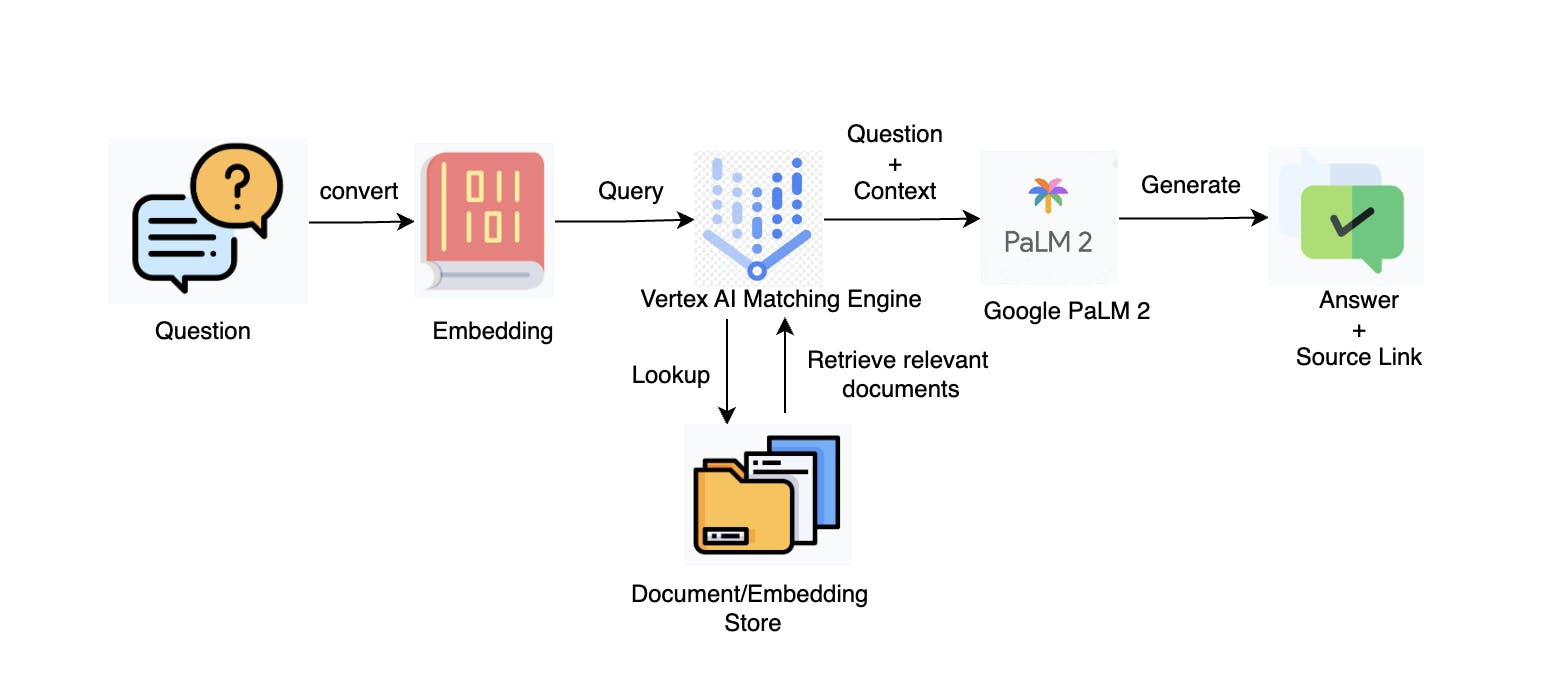
Vertex AI Matching Engine
Vertex AI Matching Engine is a powerful tool for building use cases that involve matching semantically similar items. With its high-scale and low-latency vector database, it provides the industry's leading vector similarity-matching or approximate nearest neighbor (ANN) service. Given a query item, the Matching Engine can find the most semantically similar items to it from a large corpus of candidate items. This makes it an ideal option for companies looking to efficiently retrieve relevant information from their internal knowledge base.
Implementation
Data collection and preprocessing
Help portal
HubSpot maintains the help portal articles with HTML tags and source links. This data is exported as a CSV file and preprocessing steps like removing HTML tags, special characters, etc. are performed.Notion pages
Notion provides an API to collect the data present in its pages. By using the access tokens, all the blocks from all the necessary pages are scraped and basic preprocessing steps are performed. Sample code for data scraping from Notion is available in the reference section. Depending upon the page that needs to be scraped, the code has to be modified accordingly. If the goal is to scrape all pages, then paginated requests should be called because by default Notion API shows only a certain number of pages. If a page has a link to a different page/subsection of a document, then the "has_children" key can be used to navigate to the subsection and scrape that data.
Vertex AI Embeddings
The preprocessed data (documents) needs to be converted to embeddings to store them in a vector database (Matching Engine). LangChain provides an easy integration with Vertex AI and Matching Engine. You can find the relevant links in the references section. These documents are split into chunks because of the token limit using any character of choice and converted to the embeddings and stored in the cloud storage bucket.
Matching Engine
After that, an index has to be created to search for the relevant embeddings and their documents. This index is deployed to an endpoint for reference. So, whenever a user asks a question, the question will be converted to the embeddings, and then the matching engine will search for the relevant documents with respect to the question. These documents are then added to the prompt as a context with the question and will be passed to the LLM for the answer.
Inference
The inference is done through a Slack bot, which is integrated with Google Cloud Function. The query asked to the bot is passed to the cloud function program, which calls the PALM 2 API and matching engine endpoint. The answer from the LLM is sent back to the Slack bot, which is shown to the user. There are chances that the Slack bot will show a timeout error if the response from the cloud function is not within 3 seconds. To overcome this problem, check out this link.